
内定者向け勉強会である第2回統計学レクチャーを実施しました。前回に引き続き、講師はエンジニアの田中さん。「今回はちょっと本格的な統計学の話をします」という振り出しから勉強会がスタートしました。
前回の勉強会での質問から
まずは前回の勉強会後に内定者から寄せられた質問に答えることから始まりました。
Q)統計学の勉強にはデータが必要ですが、勉強するためのデータはどのようにして手に入れたのですか?
A) Kaggleを利用しました。Kaggleと書いて「カグル」と読みます。世界中の機械学習・データサイエンスに携わっている約40万人の方が集まるコミュニティーで、そこにはデータが沢山あるんです。そこにあるデータを利用して勉強しました。
Q)どうやって情報収集しているのですか?
A)Twitterで専門家のアカウントをフォローしたり、Yahoo!ニュース、ライブドアニュース、スマートニュース、Quoraなどのニュースサイトに目を通すようにしてる。Quoraについては日本語版だけじゃなくて、英語版もチェックしたりしています。
インプットとアウトプットの理想的な割合は、インプット3:アウトプット7なのだとか。勉強会でアウトプットすることで、さらに知識を深められそうですね。
スプレッドシートで重回帰分析
質問への回答の次は、スプレッドシートでデータを開き、自分の手で重回帰分析する方法をレクチャーしていただきました。
方法は実はとても簡単。GoogleスプレッドシートのアドオンのXLMiner Analysis ToolPakを使うことで簡単に重回帰分析できてしまうのです。
さっそく、アドオンを追加して、用意されたデータをそれぞれで重回帰分析してみました。方法がわかれば1分もあれば分析できちゃうんですね。
じぶんで分析してデータから読み取る
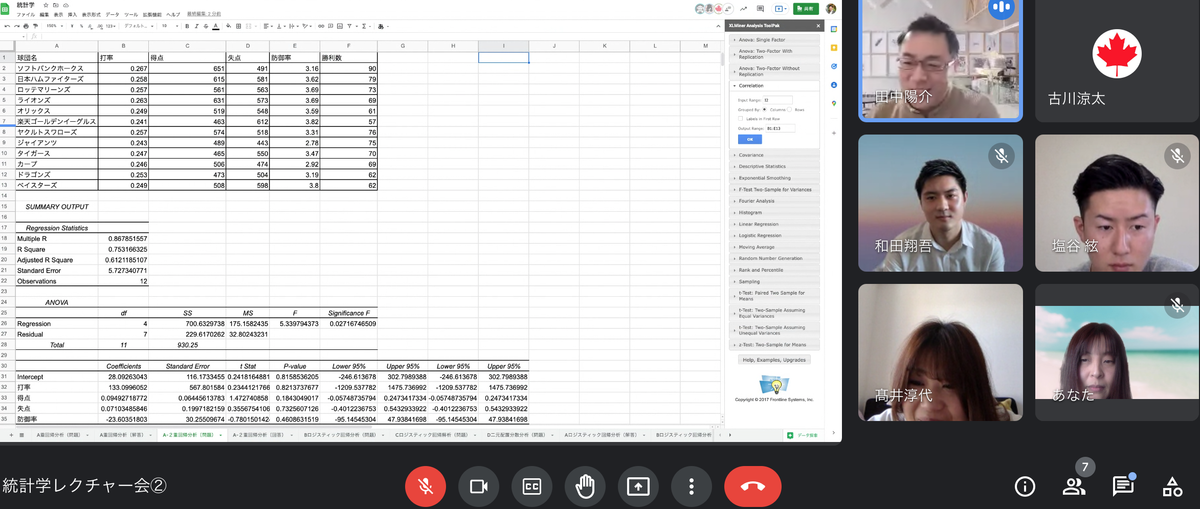
分析の操作方法を知っても、分析結果から読み取れるようにならないと仕事に生かすことはできませんよね。
そこで、新たなデータを重回帰分析して得られた結果の項目の意味と、データから推測できることを解説していただきました。
どの数値をみれば相関性が強いのか判断できるのか、どの要素が結果に大きな影響を与えているのか判断するにはどの数値をみたらいいのかなど、実践的で興味深いことを教えていただけましたよ。
まとめ
今回で統計学レクチャーは終了なのですが、これが統計学を学ぶきっかけになったら嬉しいなと思いました。内定者からみたらベテランの領域なわたしもデータ分析の流れに乗り遅れないように勉強します!
